
Arbutus Analyzer : Le fuzzy-matching ou la recherche approchée
Arbutus Analyzer : Le fuzzy-matching ou la recherche approchée
On pourrait traduire le Fuzzy-Matching par « correspondance floue » ou « correspondance approchée ».
La correspondance approchée est un domaine relativement nouveau dans son application à l’analyse et l’audit de données. Pour ceux d’entre vous qui ne connaissent pas ce terme, il s’agit d’identifier des éléments qui ne sont pas exactement les mêmes, mais qui sont suffisamment « proches » pour être considérés comme identiques.
Bien souvent, ces éléments « proches » sont en réalité le même élément qui a été saisi plus d’une fois, mais de manière légèrement différente à chaque fois.
Vous pouvez ainsi identifier des enregistrements en double, comme des noms de sociétés « Société ABC » et « Sté ABC », des numéros de factures comme 500178 et 500718 associés à des montants identiques ou approchés… etc.
Bien que la plupart de ces doublons soient généralement dus à une simple erreur de saisie, ils peuvent également s’avérer être un vecteur utilisé pour d’éventuelles fraudes.
Les recherches de correspondances approchées concernent de multiples domaines d’activité et se traduisent dans la plupart des cas par des économies directes dans la trésorerie des sociétés :
• Lorsque vous identifiez et éliminez des clients ou des fournisseurs en double, vous augmentez la productivité de vos équipes de gestion et économisez indirectement les coûts associés à la gestion des relances, aux vérifications à postériori du bien fondé des relances, des corrections à apporter aux enregistrements informatiques en cause et aux autres traitements complémentaires,
• Lorsque vous identifiez des factures qui ont été payées deux fois, cela se traduit directement par une amélioration de la trésorerie et une meilleure rentabilité.
Parmi les fonctions proposées par Analyzer dans le domaine de la correspondance approchée, on retrouvera des fonctions dédiées à la préparation des données afin de les « normaliser » et faciliter leur comparaison, des fonctions basées sur la distance Damerau-Levenshtein ainsi que des fonctions basées sur l’analyse phonétique de type Soundex.
La fonction DIFFERENCE indiquera par exemple la distance Damerau-Levenshtein, c’est-à-dire le nombre de permutations, insertions et suppressions nécessaires pour rendre deux chaînes de caractères identiques :
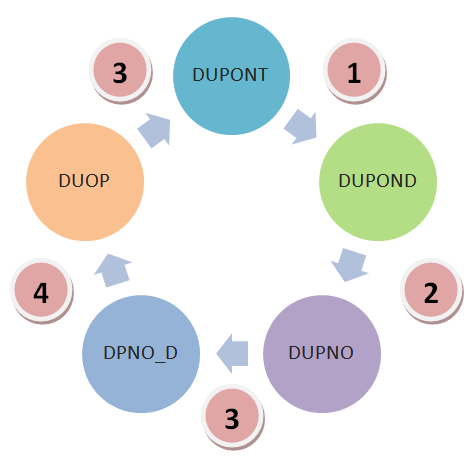
La recherche de correspondances approchées est très intensive en terme de ressources de calcul, beaucoup plus que des opérations de tri par exemple. C’est probablement le calcul le plus intensif en matière d’analyse de données puisque la demande de ressources de calcul augmente par le carré de la taille des jeux de données utilisés : lorsque vous multipliez le nombre de vos données par cent les calculs nécessaires seront multipliés par dix mille !
La raison de cette forte utilisation des ressources informatiques vient du fait que chaque enregistrement doit être comparé à tous les autres enregistrements sans exclusion car les éléments peuvent différer très légèrement sur le premier caractère, le dernier, une suite de caractères, des permutations, des données manquantes…etc.
Cela signifie qu’un test qui ne prend qu’une seconde pour 1.000 enregistrements peut prendre une semaine pour 1.000.000 enregistrements ce qui peut fortement limiter la mise en pratique de cette technique pourtant précieuse.
Pour répondre à cette problématique Arbutus Analyzer utilise des techniques de traitement parfaitement optimisées incluant de multiples technologies comme le traitement en parallèle des fonctions de recherche afin d’utiliser toute la puissance processeur mise à disposition.
Comparer un millier d’enregistrements avec Analyzer se fait instantanément et la comparaison d’un million de lignes ne prendra généralement que quelques secondes. Cette rapidité permet de tester l’intégralité de vos données même les plus volumineuses comme vos fichiers de transactions avec, à la clé, la possibilité d’identifier des factures ou autres transactions payées plus d’une fois.
Credit to Grant BRODIES - President, Arbutus Software
Arbutus Analyzer : solution pour l'audit et l'analyse informatique des données
Arbutus Analyzer : Le fuzzy-matching ou la recherche approchée
Qu’est-ce que le fuzzy-matching ?
On pourrait traduire le Fuzzy-Matching par « correspondance floue » ou « correspondance approchée ».
Cette technique consiste à identifier des éléments qui ne sont pas exactement identiques mais qui sont suffisamment proches pour être considérés comme équivalents.
Elle est particulièrement utile lorsqu’un même élément a été saisi plusieurs fois avec des variations mineures.
Pourquoi utiliser le fuzzy-matching ?
Le fuzzy-matching permet d’identifier des doublons, comme :
- Des noms de sociétés : « Société ABC » et « Sté ABC »
- Des numéros de factures : 500178 et 500718
- Des transactions avec des montants identiques ou similaires
Un enjeu clé : si certains de ces doublons sont dus à des erreurs de saisie, ils peuvent aussi être le signe de fraudes potentielles.
Les avantages concrets du fuzzy-matching
Des économies directes pour les entreprises
La recherche de correspondances approchées impacte directement la gestion financière et opérationnelle des entreprises :
- Élimination des clients et fournisseurs en double pour optimiser la gestion
- Identification des paiements en double pour améliorer la trésorerie
Les méthodes utilisées par Arbutus Analyzer
Arbutus Analyzer propose plusieurs techniques de fuzzy-matching :
- Préparation et normalisation des données
- Distance Damerau-Levenshtein
- Analyse phonétique Soundex
Parmi les fonctions proposées par Analyzer dans le domaine de la correspondance approchée, on retrouvera des fonctions dédiées à la préparation des données afin de les « normaliser » et faciliter leur comparaison, des fonctions basées sur la distance Damerau-Levenshtein ainsi que des fonctions basées sur l’analyse phonétique de type Soundex.
Par exemple, la fonction DIFFERENCE indiquera par exemple la distance Damerau-Levenshtein, c’est-à-dire le nombre de permutations, insertions et suppressions nécessaires pour rendre deux chaînes de caractères identiques :
Un défi technique majeur
La recherche approchée est très gourmande en ressources : la charge de calcul croît exponentiellement avec la taille des données.
Un test qui prend une seconde pour 1 000 enregistrements peut nécessiter une semaine pour 1 000 000 d’enregistrements !
L’optimisation des performances avec Arbutus Analyzer
Pour surmonter ce défi, Arbutus Analyzer utilise des technologies avancées :
- Traitement en parallèle des recherches
- Optimisation des algorithmes de comparaison
- Utilisation efficace des ressources processeur
Grâce à ces optimisations, comparer un million de lignes ne prend que quelques secondes.
Conclusion
Le fuzzy-matching est une technique puissante permettant d’identifier des erreurs et des fraudes tout en optimisant la gestion des données.
Avec Arbutus Analyzer, les entreprises peuvent appliquer ces techniques sur des volumes massifs de données avec une efficacité optimale.
Comparer un millier d’enregistrements avec Analyzer se fait instantanément et la comparaison d’un million de lignes ne prendra généralement que quelques secondes. Cette rapidité permet de tester l’intégralité de vos données même les plus volumineuses comme vos fichiers de transactions avec, à la clé, la possibilité d’identifier des factures ou autres transactions payées plus d’une fois.
INTUINEO EST DISTRIBUTEUR AGRÉÉ DES SOLUTIONS ARBUTUS SOFTWARE
L'analyse de données reste plus que jamais cruciale pour garantir l'intégrité et la conformité de vos processus. Les solutions d'analyse avancées d'Arbutus Analyzer facilitent considérablement cette démarche en renforçant la fiabilité des contrôles.
Pour découvrir comment Arbutus Analyzer peut transformer votre approche de l'analyse de données et de l'audit, l'équipe d'Experts Intuineo se tient à votre disposition pour une démonstration personnalisée adaptée à vos besoins spécifiques.
Vous avez des questions complémentaires ?
Notre équipe est à votre disposition pour vous accompagner
Intuineo SAS
Immeuble Skyline
22 mail Pablo Picasso
44000 Nantes
Tél +33 (0)2 40 95 38 40